

The Future Usage of Smart Phones
by Rajakumar Arul (Student Member, IEEE), Gunasekaran Raja (Member, IEEE), Sudha Anbalagan, Dhananjay Kumar, Ali Kashif Bashir (Senior Member, IEEE)
IEEE Internet Initiative eNewsletter, March 2017
Discuss this topic on Collabratec:
![]()
Proliferation of the smartphone industry has made devices user-friendly, yet people with low or no visual ability have difficulty using them. The usage of smartphones is not always convenient, especially under certain circumstances such as travelling on a public transport, in social gatherings or when busy working. Senior citizens also experience difficulty in using new technologies[20]. Therefore, today, most senior citizens in our society prefer to use traditional phones rather than smart devices.
Age is one of the major factors that restrict people in adapting new technologies. People over 70 years old often suffer memory loss and have difficulty in learning the usage of technical gadgets. Several gadgets, like blood sugar-level and blood pressure monitors, are designed for them, yet they need assistance in operating them[20]. Apart from memory loss, poor vision and the user unfriendliness of technologies are other challenges that need to be addressed. For example, a grandmother is gifted with a smartphone powered by iOS/Android. She requires a mail ID to use it, though she does not need one otherwise and also needs some assistance to create one. After creating, she has difficulty in remembering the password. This leads us to a scenario that requires designing of interactive devices that are easy to use for senior citizens.
Another motivating scenario for interactive designing of mobile phones is for kids. Currently, the number of children participating in outdoor activities is decreasing. Rather they prefer to stay indoors and lock their potential by playing video games. So any device without interactive user interface will drain their interest in digital equipment. One of the easiest ways to do so is enabling devices with voice recognition. So they can operate devices using voice instead of complicated manual inputs.
The time is not far off when we will be operating our devices with voice. With some of the services like Google assistant, Cortana voice, etc., people have started using voice commands for browsing and typing. These services use online engines to convert voice into desired input. In the near future, the quality of these services will improve in terms of efficiency and voice recognition. Siri, an Apple application, is a good voice interpreter which understands the voice efficiently and does almost all operations required in the smartphone. Siri offers excellent features, but it still requires the keywords of the official language.
To meet the challenges of interactive interface with voice recognition [5][7][8][18][19], those of us at NGNLabs and Anna University are working with an aim of facilitating minors and visually impaired in using smartphones without much physical interaction with the device. Resultantly, our work will increase the number of smartphone and the internet users.
This proposed Intelligent Interactive Interface (I3) system will have a processor like Nios II [9] to do all the processing that is being connected with the memory controller, and it has an LED display[6] to display only the components which are powered ON or OFF. It has a language analyser to differentiate the input language as colloquialism or official/formal language [17]. Dialect differentiator similar to multilayer perceptron (MLP) is used here that acts as a classifier, since the usage of mother tongue differs among people[4]. The jargon of the mother tongue, repetitive words, pause and pace being maintained throughout the talk follow a unique pattern for every individual. With the uniqueness of speech/talk the users can unlock the device and it can be operated only by the unique voice that it has been paired with or with a secured password. As we know, there exists a unique pattern between diverse voice and mother tongue cognition; our system should never lead to confusion even when a very large number of accents are spoken. In non-acoustic environments, our proposed design should act as a clean speech recognizer to recognize the voice it has been paired with. The mirror casting module casts the visual stream content to other nearby visual units like television, monitors, etc. to see the required visual outcome of the device [11]-[13]. The voice synthesizer plays a vital role in our design, which adds the predicted noise or tone that is commonly produced by an individual and checks for the unique pattern it obtained already. This way, we authenticate the voice paired with the device. It also has GSM/LTE and wireless broadband modules to provide voice and data connectivity using internet backhaul [15].
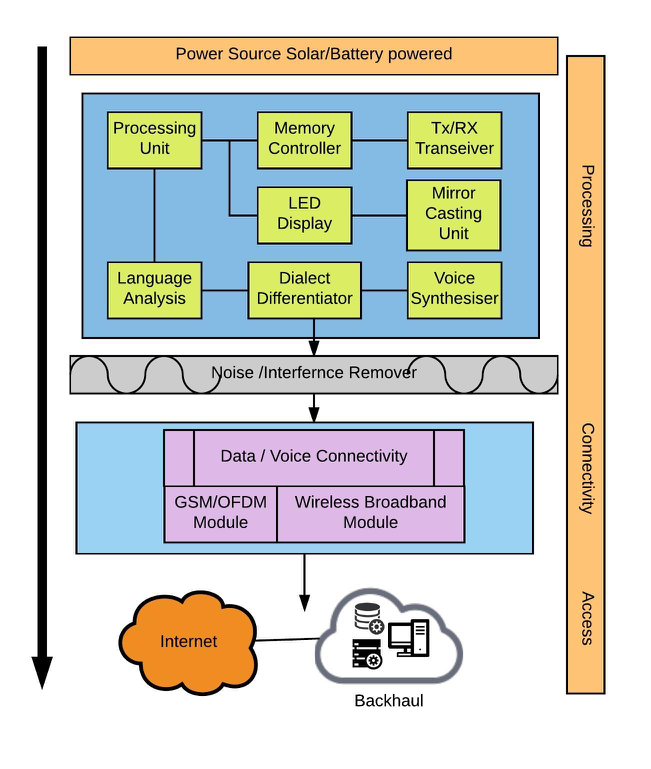
Figure 1. Components in the I3 Model
The proposed I3 model in Figure1 will adapt any short-run change of user voice, and an alteration in usage of words must also be learned by the learning network (artificial intelligence) that is inculcated in the device. Difference and distribution of voice is being identified by the energy at different frequencies. As per the neuro-heuristic voice recognition [10], the speech recognition system is under research and there exists a synchronism of voice as our brain stimulus responds immediately to recognition of voice (i.e., to find if the particular voice belongs to a known person or not). Not only the human brain, but even animals/birds can find their young ones among groups using voice as a primary mode and vice versa. So there is strong evidence seen that each and every voice possesses a unique pattern [21]. Owing to the enormous and tremendous improvements in all fields, designing a circuit which recognizes uniqueness among various voices will be developed in the near future.
Acknowledgment
Rajakumar Arul, Gunasekaran Raja, gratefully acknowledges support from NGNLabs, Department of Computer Technology, Anna University, Chennai
References:
[1] Ranny, “Voice Recognition using k Nearest Neighbour and Double Distance Method”, IEEE Communications, 2016.
[2] Haiyan JIN, Shaopeng ZHAO, “A new parallel instruction model based on multi-tasking bluetooth communication”, 12th International Conference on Computational Intelligence and Security, IEEE Computer Society, 2016.
[3] Syu-Siang Wang, Hsin-Te Hwang, Ying-Hui Lai, Yu Tsao, Xugang Lu, Hsin-Min WangandBorching Su, “Improving Denoising Auto-encoder based Speech Enhancement with the Speech Parameter Generation Algorithm”, Proceedings of APSIPA Annual Summit and Conference, 2015.
[4] Felipe Gomes Barbosa, Washington Lu´ıs Santos Silva, “Automatic Voice Recognition System based on Multiple Support Vector Machines and Mel-Frequency Cepstral Coefficients”, 11th International Conference on Natural Computation (ICNC), 2015.
[5] Nacereddine Hammami, MouldiBedda, Nadir Farah, Raouf Ouanis Lakehal-Ayat, “Spoken Arabic Digits recognition based on (GMM) for e-Quran voice browsing: Application for blind category”, Taibah University International Conference on Advances in Information Technology for the Holy Quran and Its Sciences, 2013.
[6] Meng Mu (MengMu), “Analysis of the Failure Mechanisms for LED Display and the Preventive Solutions”, IEEE Communications Magazine, 2014.
[7] James R. Evans, Wayne A. Tjoland and Lloyd G. Allred, “Achieving a Hands-Free Computer Interface using Voice Recognition Speech Synthesis”, IEEE AES Systems Magazine, January 2000, pp. 14-16.
[8] Ngoc C. Bui, Jean J. Monbaron, And Jean G. Michel, “An Integrated Voice Recognition System”, IEEE Transactions on Acoustics, Speech, and Signal Processing, Vol.31, No. 1, February 1983.
[9] Ge Zhang, Jinghua Yin-, Qian Liu, Chao Yang, “A Real-Time Speech Recognition System Based on the Implementation ofFPGA”, Cross Strait Quad-Regional Radio Science and Wireless Technology Conference, July 26-30, 2011, pp. 1375-1378.
[10] Dawid Połap, “Neuro-heuristic voice recognition”, IEEE Proceedings of the Federated Conference on Computer Science and Information Systems, ACSIS, Vol. 8, pp. 487–490.
[11] David Aldrich, “Video Screen casting: A Recipe for Automation”, University of Washington, September 2007.
[12] Intel Pro, “Wireless Display White Paper”, 2012
[13] Wi-Fi Certified Miracast, “Extending the Wi-Fi experience to seamless video display”,
Wi-Fi Alliance, September, 2012.
[14] Geoffrey G. Zweig, “Speech Recognition with Dynamic Bayesian Networks”, University of California, Berkeley, Spring 1998.
[15] Nathan Souvira`a-Labastie, St´ephaneRagot, “On the applicability of the SBC codec to support super-wideband speech in Bluetooth handsfree communications”, Orange Labs, Lannion, France.
[16] Atsushi Ito, Takuya Kato, Hiroyuki Hatano, Mie Sato, Yu Watanabe, Eiji Utsunomiya, “A Study on Designing Ad Hoc Network Protocol using Bluetooth Low Energy”, 7th IEEE International Conference on Cognitive Infocommunications, October 16-18, 2016,
pp. 109-114.
[17] Christian Vazquez-Machado and Pedro Colon-Hernandez, Pedro A. Torres-Carrasquillo, “I-Vector Speaker and Language Recognition System on Android”, IEEE, 2016.
[18] Hyan-SooBae, Ho-Jin Lee, Suk-Gyu Lee, “Voice Recognition based on Adaptive MFCC and Deep Learning”, IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), 2016, pp. 1542-1546.
[19] Katrin Kirchhoff, “Robust Speech Recognition using articulatory information”, International Computer Science Institute, August 1998.
[20] Hazwani Mohd Mohadis and Nazlena Mohamad Ali, “A Study of Smartphone Usage and Barriers among the Elderly”, IEEE 3rd International Conference on User Science and Engineering (i-USEr) 2014, pp. 109-114.
[21] Naresh P. Trilok, Sung-Hyuk Cha, and Charles C. Tappert , “ Establishing the uniqueness of the human voice for security applications”, Proceedings of Student/Faculty Research Day, CSIS, Pace University, 2004, pp. 8.1- 8.6.Intel Pro, “Wireless Display White Paper”, 2012
 Rajakumar Arul
Rajakumar Arul
Rajakumar Arul pursued his Bachelor of Engineering in Computer Science and Engineering from Anna University, Coimbatore. He received his Masters in Computer Science and Engineering at Anna University - MIT Campus. Currently, he is doing Doctorate of Philosophy under the Faculty of Information and Communication in NGNLabs, Department of Computer Technology, Anna University - MIT Campus. He is a recipient of Anna Centenary Research Fellowship. His research interest includes Security in 5G, Broadband Wireless Networks, WiMAX, LTE, Robust resource allocation schemes in Mobile Communication Networks.
 Gunasekaran Raja
Gunasekaran Raja
Gunasekaran Raja is an Associate Professor in Department of Computer Technology at Anna University, Chennai and also the Principal Investigator of NGNLabs. He received his B.E degree in Computer Science and Engineering from University of Madras in 2001, a M.E in Computer Science and Engineering from Bharathiyar University in 2003, and the Ph.D in Faculty of Information and Communication Engineering from Anna University, Chennai in 2010. He was a Post-Doctoral Fellow from University of California, Davis, USA, 2014-2015. He was a recipient of Young Engineer Award from Institution of Engineers India (IEI) in 2009 and FastTrack grant for Young Scientist from Department of Science and Technology (DST) in 2011. Current research interest includes 5G Networks, LTE-Advanced, Wireless Security, Mobile Database and Data Offloading. He is a member of IEEE, Senior member of ACM, CSI and ISTE.
 Sudha Anbalagan
Sudha Anbalagan
Sudha Anbalagan received her B.Tech degree in Information Technology from Amrita University, Coimbatore, M.E degree in Computer Science and Engineering from Anna University, Chennai. Currently she is a Ph.D. scholar in Department of Information Technology, Anna University, MIT Campus. She was also a visiting research fellow for a period of 9 months with the Department of Computer Science, University of California, Davis, USA. Her research interest includes 5G, LTE-A, Software Defined Networking, Data Offloading and Network Security.
 Dhananjay Kumar
Dhananjay Kumar
Dhananjay Kumar received his Ph.D. degree under the Faculty of Information andCommunication Engineering at Anna University, Chennai. He did his M. E. in IndustrialElectronics Engineering, at Maharaja Sayajirao University of Baroda and M. Tech. inCommunication Engineering at Pondicherry Engineering College, Pondicherry. He is currentlyworking as Associate professor in Dept. of Information Technology, Anna University, MITCampus, Chennai, India. His technical interest includes mobile computing & communication,multimedia systems, and signal processing. Currently he is developing a system to supportmedical video streaming over 3G wireless networks which is sponsored by theUGC, New Delhi.
 Ali Kashif Bashir
Ali Kashif Bashir
Dr. Ali Kashif Bashir received his Ph.D. in Computer Science and Engineering from Korea University, South Korea. He has served National Institute of Technology, Nara, Japan as Assistant Professor. He has also served Graduate School of Information Science and Technology, Osaka University, Japan and National Fusion Research Institute, South Korea as Postdoc fellow. Dr. Ali is a senior member of IEEE and an active member of ACM and IEICE. He has given several invited and keynote talks and is a reviewer of top journals and conferences. His research interests include: cloud computing (NFV/SDN), network virtualization, IoT, network security, wireless networks, etc. He is also serving as editor-in-chief of the IEEE Internet Technology Policy Newsletter and IEEE Future Directions Newsletter.
Editor:
 Y. Sinan Hanay
Y. Sinan Hanay
Dr. Y. Sinan Hanay received the B.S. in Microelectronics from Sabanci University in 2005, M.S. in Electrical Engineering from TOBB University of Economics and Technology, Turkey in 2007 and Ph.D. in Electrical and Computer Engineering from University of Massachusetts (UMass), Amherst in 2011. During his graduate studies, he worked as a teaching and research assistant at UMass.
He joined Osaka University in 2011 as a post-doctoral researcher. From 2012 to 2016, he worked at Center for Information and Neural Networks (CiNet) of NICT Japan. During that time, he also held visiting researcher and lecturer positions at Osaka University. He is a co-author of a paper which received the best paper award in IEEE International Conference on High Performance Switching and Routing 2011. His research interests include computer networks and machine learning. He is currently an assistant professor at TED University in Turkey.
Article Contributions Welcomed
If you wish to have an internet policy related article considered for publication, please contact the Managing Editor of Technology Policy and Ethics IEEE Future Directions Newsletter.
Past Issues
IEEE Internet Policy Newsletter Editorial Board
Dr. Ali Kashif Bashir, Interim Editor-in- Chief
Dr. Syed Hassan Ahmed
Dr. Mudassar Ahmad
Dr. Onur Alparslan
Dr. Muhammad Bilal
Dr. Syed Ahmad Chan Bukhari
Dr. Ankur Chattopadhyay
Dr. Junaid Chaudhry
Dr. Waleed Ejaz
Dr. Yasir Faheem
Dr. Prasun Ghosal
Dr. Tahir Hameed
Dr. Y. Sinan Hanay
Dr. Shagufta Henna
Dr. Fatima Hussain
Dr. Rasheed Hussain
Dr. Saman Iftikhar
Dr. Stephan Jones
Dr. Mohammad Saud Khan
Olga Kiconco
Dr. Jay Ramesh Merja
Dr. Mubashir Husain Rehmani
Dr. Hafiz Maher Ali Zeeshan
About: This newsletter features technical, policy, social, governmental, but not political commentary related to the internet. Its contents reflect the viewpoints of the authors and do not necessarily reflect the positions and views of IEEE. It is published by the IEEE Internet Initiative to enhance knowledge and promote discussion of the issues addressed.